
The first two parts of this series introduced machine learning concepts and outlined key roles for delivering insight. Now, let’s discuss how to leverage an iterative process for designing, building and implementing machine learning solutions that solve strategic business problems. A common methodology with wide-spread adoption is the data mining process framework called CRISP-DM. The framework was first introduced in the late 1990’s by a consortium of data-focused corporations searching for a structured approach to analyze data. With the growth of machine learning, the framework has evolved into a standard methodology for building analytical applications. There have been many variations of the framework since its inception but the core principles remain the same:
- Define the business problem and align with strategic goals.
- Ensure the right data is available.
- Iteratively build and validate the model.
- Deploy the solution within the business.
In general, CRISP-DM is a set of tasks organized into six phases that comprise an integrated development lifecycle. Each phase is aligned to a core principle and provides requisite input for the next phase in the process.
Understanding the Business Problem
The first step to a successful analysis project is to define the business problem and corresponding data analysis goals. The Business Understanding phase is an opportunity for all stakeholders to understand and agree upon the proposed business solution. The output of this phase defines the scope needed for the project, which leads to the next phase of work.
Understanding the Data
The objective of the Data Understanding phase is to ensure the right data is available. The project team is focused on exploring and acquiring data from multiples data sources whether internal or external to the business. This is an opportunity to conduct exploratory data analysis in order to gain initial insights. These insights are then compared to the data analysis goals to ensure feasibility of the proposed business solution. Often times various analysis techniques such as descriptive statistics and clustering are employed to better understand the data beyond summaries.
Preparing Data for Analysis
With a deeper understanding of data, the next phase is Data Preparation. At this point, the team is focused on engineering tasks such as data ingestion, data cleansing, transformation and, if necessary, automation of data preparation processes. Similar to other data-related projects such as data warehousing or business intelligence, the Data Preparation phase aims to ensure data quality and consistency within a systematic approach. In addition, this phase will also design processes that are specific to machine learning techniques. For example, the accuracy of many algorithms is dependent upon the format of data values. Missing values may need to be imputed to ensure records are not inadvertently removed when the model is executed. Categorical attributes with characters values may need to be transformed to numbers.
Building the Model
It’s now time to build the model using machine learning techniques that support the pre-defined data analysis goals defined during the Business Understanding phase. Aligned with building the model is the evaluation of the model’s accuracy. Modeling and Evaluation are separate phases in the CRISP-DM framework, but in reality they typically work as one iterative phase. As described in part-one of this series, machine learning can be supervised – correct answers are given to the algorithm in advance; or unsupervised – no answers are provided in advance and the algorithm must group data into different classifications. Often times, multiple techniques can be used when modeling a solution. Clustering techniques (unsupervised) can be used to find natural data groups followed by classification (supervised) techniques to determine how new data should be grouped.
Deploying the Solution
The last step of the framework is deployment of the solution within the appropriate business process. Machine learning solutions are often embedded in operational processes where the solution can prescribe an action as it continues to learn from the ingestion of new data values. It may be deployed within real-time transactions or recurring batch processes. Monitoring the solution deployed within a business process may uncover opportunities for model improvements therefore spawning new development.
Identifying the Right Roles
As previously outlined in our series, there are numerous roles within a machine learning project. The roles include domain experts, platform/tools specialists, data engineers, data scientists and data visualization specialists. Typically, these roles are engaged in the full development lifecycle however some phases may have higher priorities for specific roles. For example, the Business Understanding phase will be a key priority for domain experts although their business knowledge will be required for Data Understanding and Evaluation. Data Engineers will be the primary role for Data Preparation. Platform/Tools Specialist will engage in Data Preparation and Deployment phases. Data Visualization roles can help define the solution during Business Understanding in addition to designing how the model can be consumed during the Modeling phase. The Data Scientist is usually engaged in the entire lifecycle especially if the role is perceived as a solution architect.
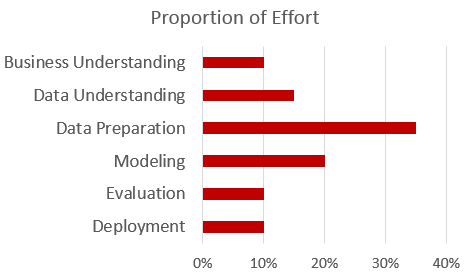
Another consideration is the allocation of effort within the framework. In other words, which phases take the greatest amount of time to complete? The Modeling phase is perceived as the most complex, but the greatest proportion of effort is normally the Data Preparation phase. Success factors for many machine learning projects are data quality and standardization.
Delivering Value
There are numerous development lifecycle methodologies but the CRISP-DM framework is the most widely used for analytic initiatives. It provides an approach for aligning business objectives with data analysis goals to ensure solutions are accurate and effective. Regardless, delivering the value of machine learning is dependent upon a structured, iterative approach for managing deliverables and expectations. This approach, which must also be flexible to change in order to solve strategic business problems.


