A lot of teams quietly gave up on Microsoft Copilot a year ago. The tools have changed far more than the impression they left behind. We put that to the test — and the results point to an opportunity most organizations are missing.
Over the past year, we’ve heard a consistent message from colleagues and clients: “We tried Copilot, it underwhelmed us, and we moved on.” It’s an understandable reaction. Early enterprise copilots were uneven, and first impressions are sticky.
But the products underneath those impressions have changed substantially. Copilot can now run Anthropic’s Claude models alongside OpenAI’s, and reasoning-heavy ‘think deeper’ modes are widely available. The gap between the best and worst configurations, though, is enormous. For many organizations, the issue today isn’t that the tools are weak — it’s that almost no one is using them the way that actually works.
To pressure-test that idea, one of our consultants, Chris Ventura, ran a structured, hands-on comparison.
What We Tested
We took a single everyday task — analyzing a spreadsheet with more than 100,000 data points — and turned it into 115 specific questions and calculations. Then we ran that exact same task across 12 different model-and-settings configurations: different models (ChatGPT 5.x, and Claude Opus, Sonnet, and Fable 5), different reasoning-effort levels, and different access paths — Claude used directly from Anthropic, Claude inside Copilot, and Copilot’s own agents and “auto” modes. Every run was scored against the same rubric, by hand, with no AI assistance.
A note on scope, because it matters: these are everyday personal-productivity tasks, the kind an average user runs in a normal workday. The difficulty is realistic but deliberately moderate. On substantially harder work, the rankings would likely shift. We’re sharing these as directional findings from an internal hands-on test, not as a formal published benchmark.
What We Found
Four things stood out.
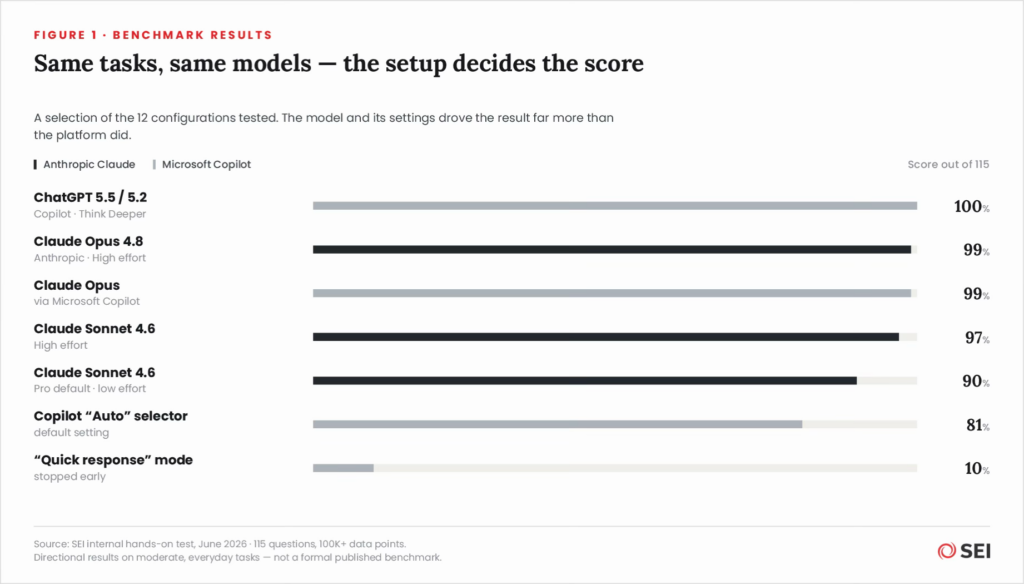
- The model matters more than the platform. The top Claude models and the “deep-think” ChatGPT models all clustered between 97% and 100% — whether they were accessed directly or through Copilot. The brand on the login page mattered far less than the engine doing the work.
- The defaults are rarely the right setting. This was the most actionable finding. Copilot’s “Auto” model selector landed at 81%. Claude’s standard professional default — Sonnet on a low reasoning effort — scored 90%. That same Sonnet model, set to high effort, reached 97%. Same model, very different result, decided entirely by a setting most users never touch.
- Reasoning effort is the second-biggest lever. Across the board, turning the effort setting up moved scores by roughly 7 to 10 points. It is the single easiest quality improvement available — and it is almost always left on the lowest setting.
- Claude inside Copilot performed on par with Claude direct. When effort was set to high, Claude Opus accessed through Copilot scored essentially the same as Claude accessed straight from Anthropic. For organizations already standardized on Microsoft, that is a meaningful and underappreciated result.
There was also a cautionary note at the bottom of the table: the “quick response” modes flopped, scoring around 10% because they stopped early and never finished the work. Convenience settings that feel faster can quietly cost you the entire result.
This is an Education Problem, Not a Tool Problem
Step back from the numbers and a pattern emerges. The difference between a top-tier result and a mediocre one usually wasn’t the platform, or even the model. It was knowing which model to choose, which setting to turn up, and which “convenient” mode to avoid. None of that is obvious, and none of it is enabled by default.
This is exactly the gap we see inside organizations. Companies buy licenses, switch on a tool, and assume value will follow. What actually follows is a wide range of outcomes: a few power users quietly getting excellent results, a large middle getting mediocre ones, and a group that tried the default once, wasn’t impressed, and walked away — taking their impression of the entire category with them.
The teams that get real value aren’t using better tools. They’re using the same tools deliberately.
How SEI Helps Clients Close the Gap
This is the work we do: helping organizations move from license deployment to genuine business value. For copilot rollouts specifically, that means a few things.

- Readiness and use cases. We assess whether the organization is ready from a data, security, and governance standpoint, and we map the specific workflows where AI genuinely helps — rather than rolling it out generically and hoping.
- Model and setting guidance. We help teams match the right model and reasoning effort to the task at hand, so people aren’t unknowingly defaulting to the weakest configuration.
- Governance and guardrails. We put acceptable-use standards, output-validation habits, and review practices in place so adoption stays safe and compliant.
- Role-based training and adoption. We run executive briefings, “prompting for productivity” workshops, and role-specific playbooks, then sustain adoption with champions, office hours, and feedback loops that turn early pilots into repeatable, measurable use.
We’ve done this across enterprise rollouts, and the lesson is consistent with what this test shows: the tool is rarely the bottleneck. The model choice, the settings, and the habits around them are — and all three are teachable.
A Second Look May Be Worth It
If your organization tried a copilot, came away unimpressed, and quietly shelved it, it may be worth revisiting — this time with the configuration and enablement that today’s tools reward. That’s a conversation we’re always glad to have. To talk about an AI readiness assessment or a copilot enablement program, get in touch with us today!